使用NotebookLM有了一段时间,但使用频率不是很频繁:一个是网络连接的问题,一个是总觉得单纯的一问一答(然后保存对话产出)没啥大用。
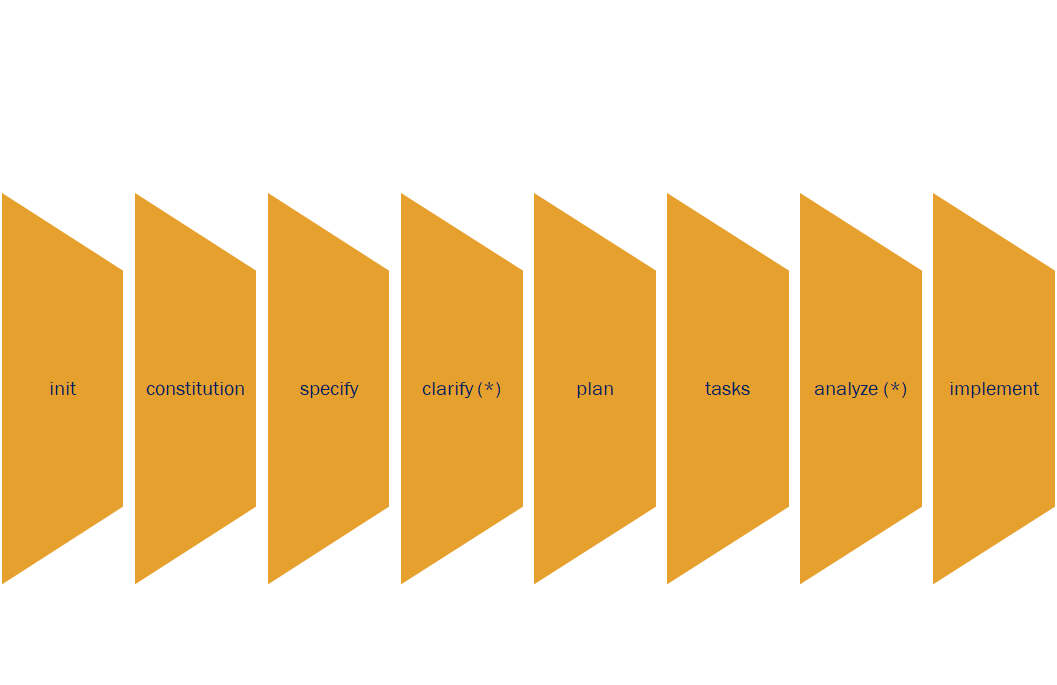
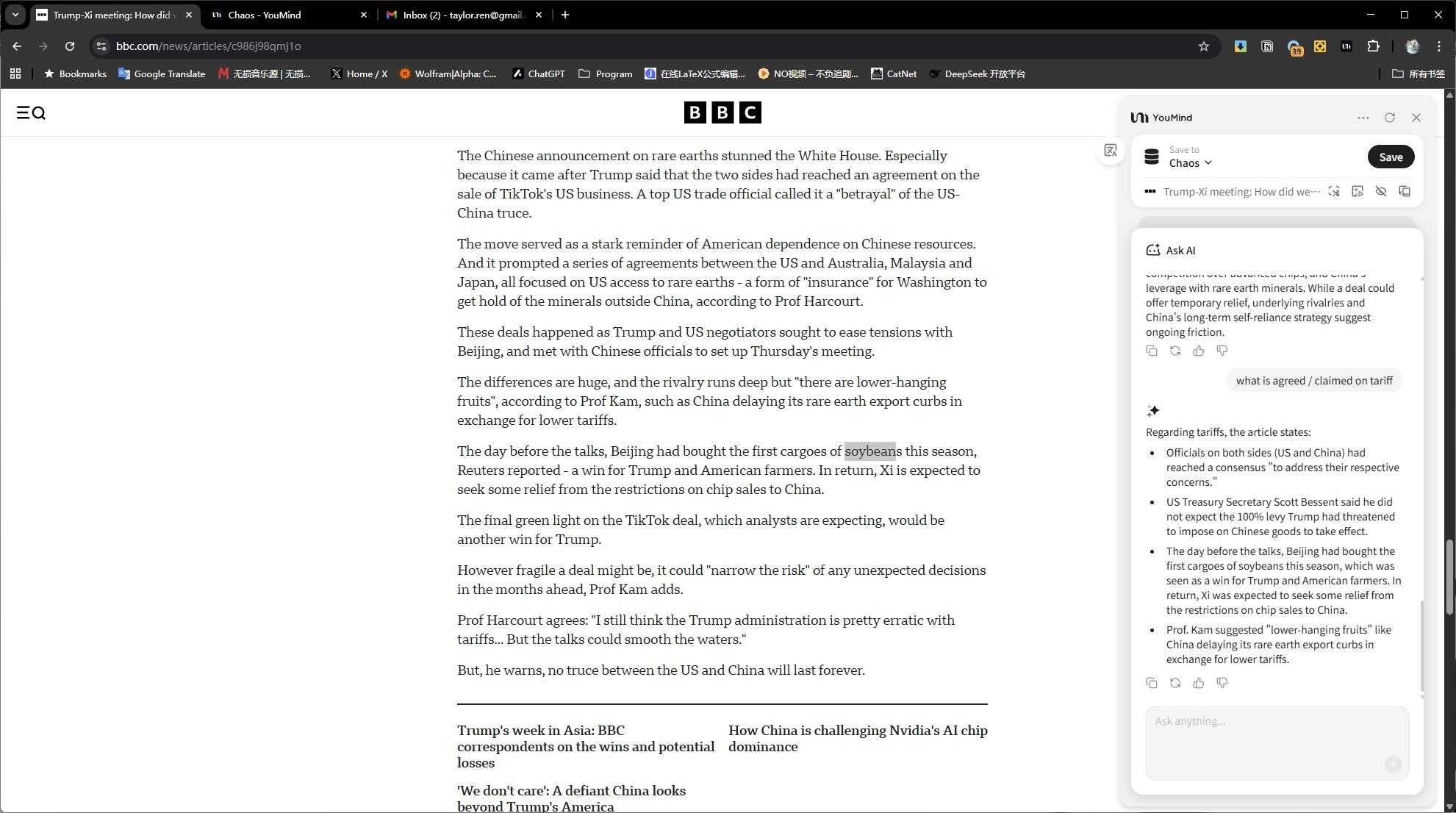
前两天为了测试网络连接,又跑上去看了一下,发现有了很多改进,NLM提供了更多的“探索”资源的方式。我让它做了一些“探索”,并表示满意:它的总结基本不会漏东西,并且用AI独有的“联想”为我找到了我之前也没有意识到的connection——而经过我的reflection,这样的connection确实还是有道理的。
(more…)
使用NotebookLM有了一段时间,但使用频率不是很频繁:一个是网络连接的问题,一个是总觉得单纯的一问一答(然后保存对话产出)没啥大用。
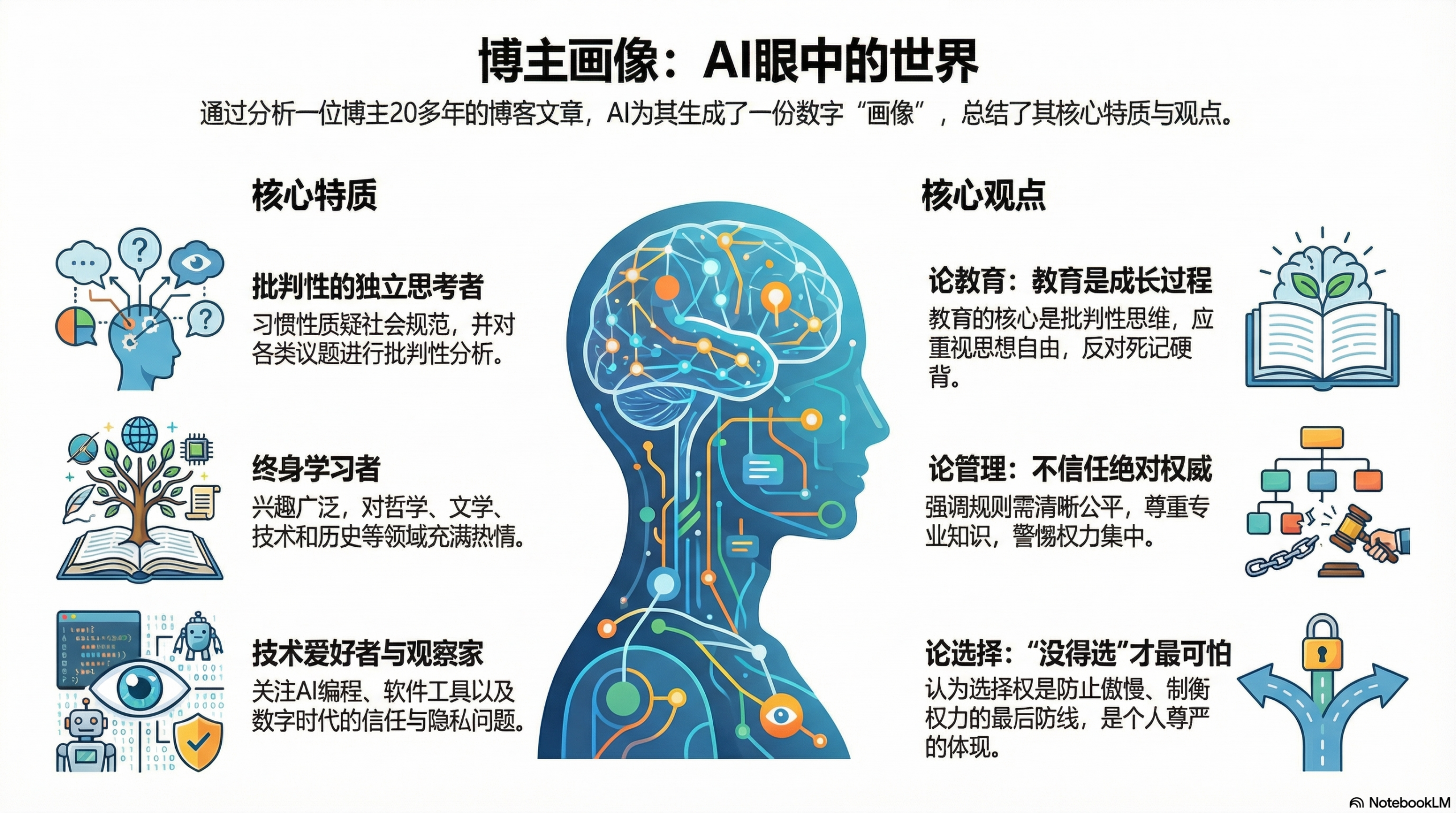
前两天为了测试网络连接,又跑上去看了一下,发现有了很多改进,NLM提供了更多的“探索”资源的方式。我让它做了一些“探索”,并表示满意:它的总结基本不会漏东西,并且用AI独有的“联想”为我找到了我之前也没有意识到的connection——而经过我的reflection,这样的connection确实还是有道理的。
(more…)

引言
要说我们最不缺的,就是“surprise”。
前天看到这么一篇文章:《备案才能笑?相声的脊椎正在被抽走》。这真的是一个比大菜更surprise的surprise——其实,我也不是那么surprise。
第一部分:艺术的“脊椎”与“条条框框”
(more…)