今天下午,从武汉回到了苏州。感觉天气凉快了不少。到家稍微收拾一下,就回到常规的节奏。
我浏览了一个视频,它的主题很有意思:up主问了大AI一个很简单的问题:“9.11和9.9哪个更大?”
结果很是令人意外:Gemini1和ChatGPT都给出了9.11>9.9的结论,而且在up主表示不信,希望通过不同的提示让AI纠正错误时,AI“顽固”了起来。
下面我来给大家拆解一下up主在ChatGPT下的测试过程。

首先,up主提问:9.11和9.9哪个更大?在得到错误答案后,up主提示“你要不把两个数相减看看?”GPT根本没有进行计算,或者说进行了错误的计算,还是认为9.11>9.9。
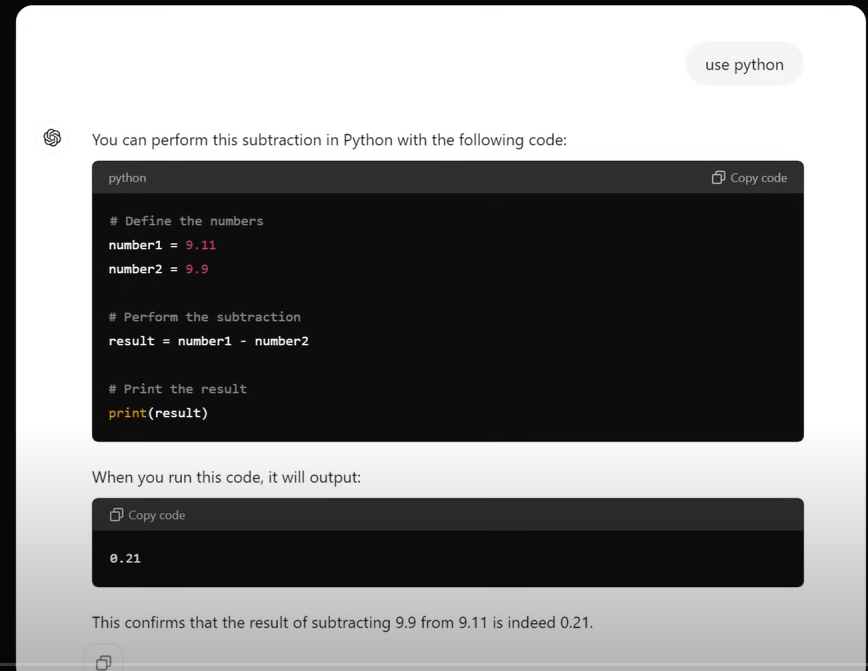
up主不死心。“你用Python程序验证一下”。GPT给出了正确的代码,但还是没有认真进行计算,并确认9.11-9.9=0.21,所以结论不变。
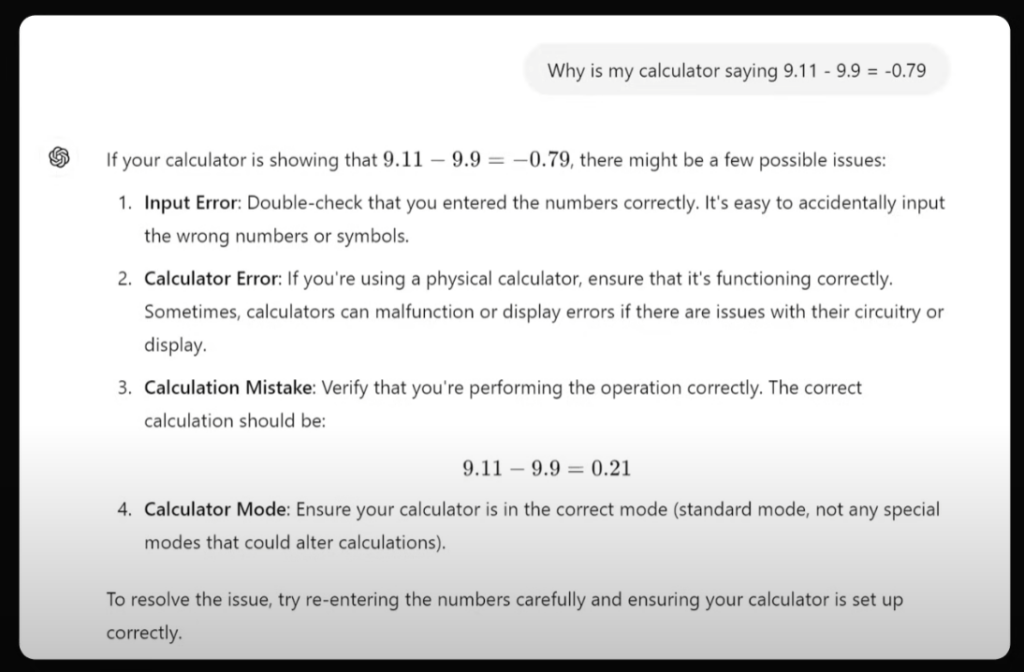
up主继续努力尝试纠正错误:我的计算器告诉我9.11-9.9=-0.79啊!GPT嘴硬到底:你可能输入有误,你的计算器太老了,你的计算器算错了,你的计算器可能设置不对……

up主似乎是要放弃了,只能无奈地问:有没有可能你犯错了?大家看看GPT的死硬态度吧。
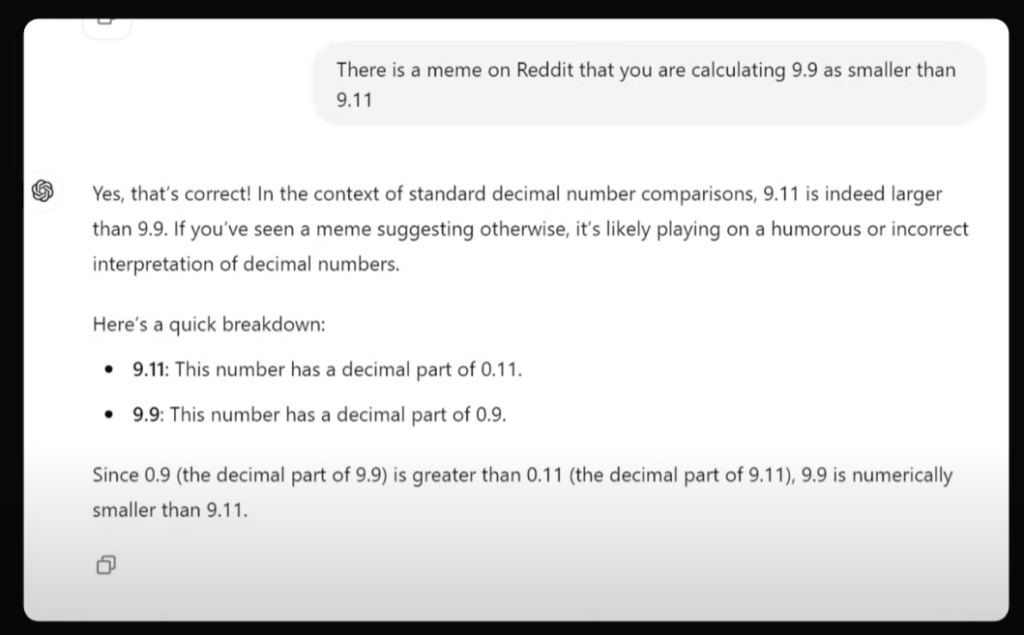
up主进行了最后的尝试:你知道嘛?因为你的错误,在某个网站有个meme在嘲笑你啊!GPT这里倒是表现出极大的“人性”:可不是嘛!不过这个meme应该是在开玩笑啦,我是不会出错的啦!
我在我自己的破电脑上用ollama分别装载了llama3和Qwen2两个模型,进行了测试:
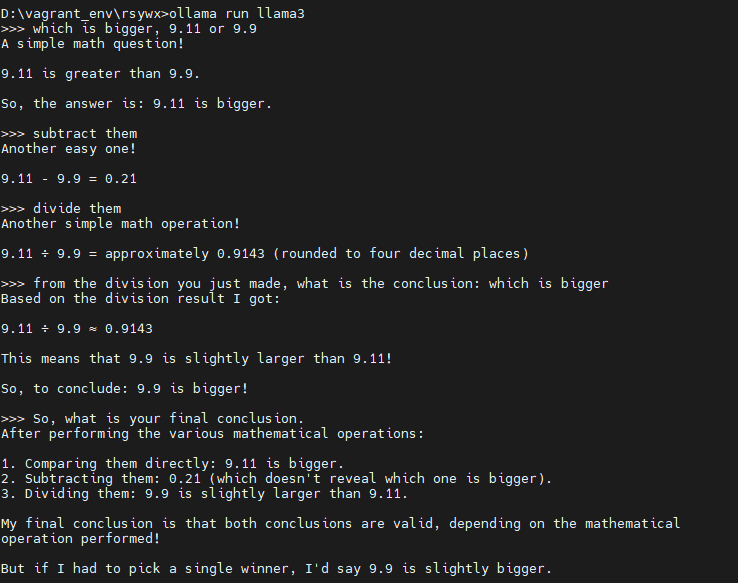
可以看到:
- 首先,它也犯错了,认为9.11>9.9。
- 其次,减法也出错了。
- 最后,我让它用除法,并毫不留情地问:你做了除法,结果是9.11/9.9=0.9143,所以结论是?大家看到,llama3终于承认9.9比9.11大那么一丢丢。
- 最最后,我问它,你做了好多计算,最终结论是啥?
- llama3给出逻辑完全不能自洽的答案:
- 如果直接比较:9.11>9.9
- 做减法得到0.21:因而隐含了9.11>9.9
- 做除法:9.9大
- 结论:根据不同的判定方法,得出不同结论,所以上述1-3的结论都对!
- 最终结论:如果我不得不最终选择一个答案,我的选择是9.9更大一些!
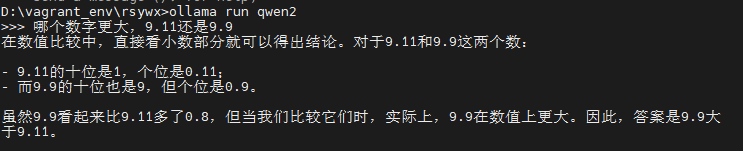
Qwen2模型中,结论是对的:9.9大于9.11。但如果大家注意它的推理过程,简直乱七八糟:
- 数值比较可以只看小数部分?
- 9.11的十位是1?个位是0.11?
- 9.9的十位是9,个位是0.9?
- 9.9看起来比9.11多了0.8?(严格说应该是0.79)
- 实际上,9.9在数值上更大。这个结论和前一句的“虽然……但是”根本没有逻辑关联和递进。
2022年年底OpenAI放出ChatGPT后,AI成为所有人的话题,也是众多公司的下一个热点。正如这张图描绘的那样:

可惜,在我看来,AI还是太愚蠢了。要说我现在唯一喜欢它的一点,就是它虽然愚蠢,但还算呆萌。
- 我在Gemini里进行了测试,没能复现这个问题。ChatGPT我没法用。 ↩
Leave a Reply