>话说天下大势,分久必合,合久必分。
2002年的时候,肾上鄙人在下我受华中科技大学出版社的委托,担任李维(Gordon)新书[《#C++Builder 6 SOAP/Web Service开发》](https://rsywx.net/books/00455.html)的技术编辑,并写了一篇前言。我在前言中,(对广义的IT界)做了一个判断:和天下大势一样,IT界的技术发展也会遵守**合-分-合-分**……这样的一个趋势。
如今套用在AI这些年的发展,我也看到了“合-分”的第一次进化。
我挺喜欢看书的,也挺喜欢看电子书——特别是有些时候,实体书搞不到,那就只能看电子书了。
之前吧,我用一个非常old的KPW3看书,也不敢抱怨:屏幕小了一点,英文单词翻译弱了一点,中文输入(比如添加笔记)拉了一点,导出功能肋了一点,售后服务是没有一点……但没有别的特别动心的选择。

Google沉寂了好一段时间,前两天放出了一个重要的模型升级:Gemma 4。我下载了、运行了。
我用的测试工具比较多,包括:Visual Studio Code(VSC)中的Github Copilot(自动选择模型),Ollama(Gemma 4 31b),还有国产的豆包。
其中,本地跑Ollama的桌面机配了一块5060 Ti 32G的显卡。

我一直用Jellyfin来管理我的媒体收藏:音乐、电影、照片等……其中的音乐收藏是我多年收集的成果,质量远超网络音乐……
不过,我不是很喜欢它自带的播放界面:没有频谱动态显示,CD封面也太小。于是我决定采用快速原型开发方式制作一个。
(more…)

从2022年底ChatGPT问世,这三年来所谓AI的发展已经令人眼花缭乱:文字对话,图像,音乐,视频,编程……几乎我们日常使用电脑的每个领域,都有了AI的参与。
我也在力图跟上这些最新技术的发展,但最大的问题在于:那时国内模型还没有跟上,而国外的模型对国内的用户又是极不友好——这就让我很羡慕朋友圈里能第一时间用到这些AI的伙计。
(more…)
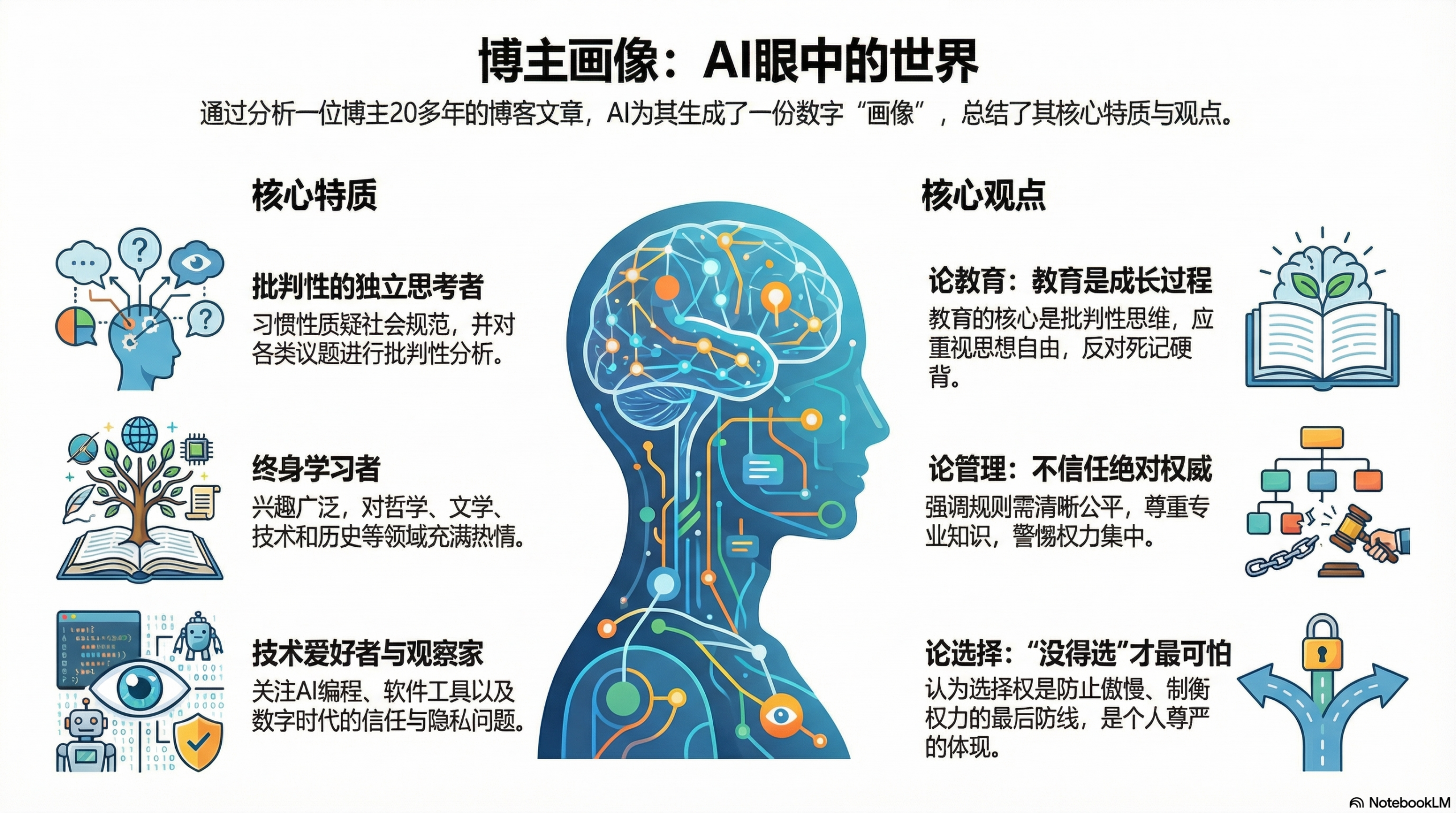
使用NotebookLM有了一段时间,但使用频率不是很频繁:一个是网络连接的问题,一个是总觉得单纯的一问一答(然后保存对话产出)没啥大用。
前两天为了测试网络连接,又跑上去看了一下,发现有了很多改进,NLM提供了更多的“探索”资源的方式。我让它做了一些“探索”,并表示满意:它的总结基本不会漏东西,并且用AI独有的“联想”为我找到了我之前也没有意识到的connection——而经过我的reflection,这样的connection确实还是有道理的。
(more…)