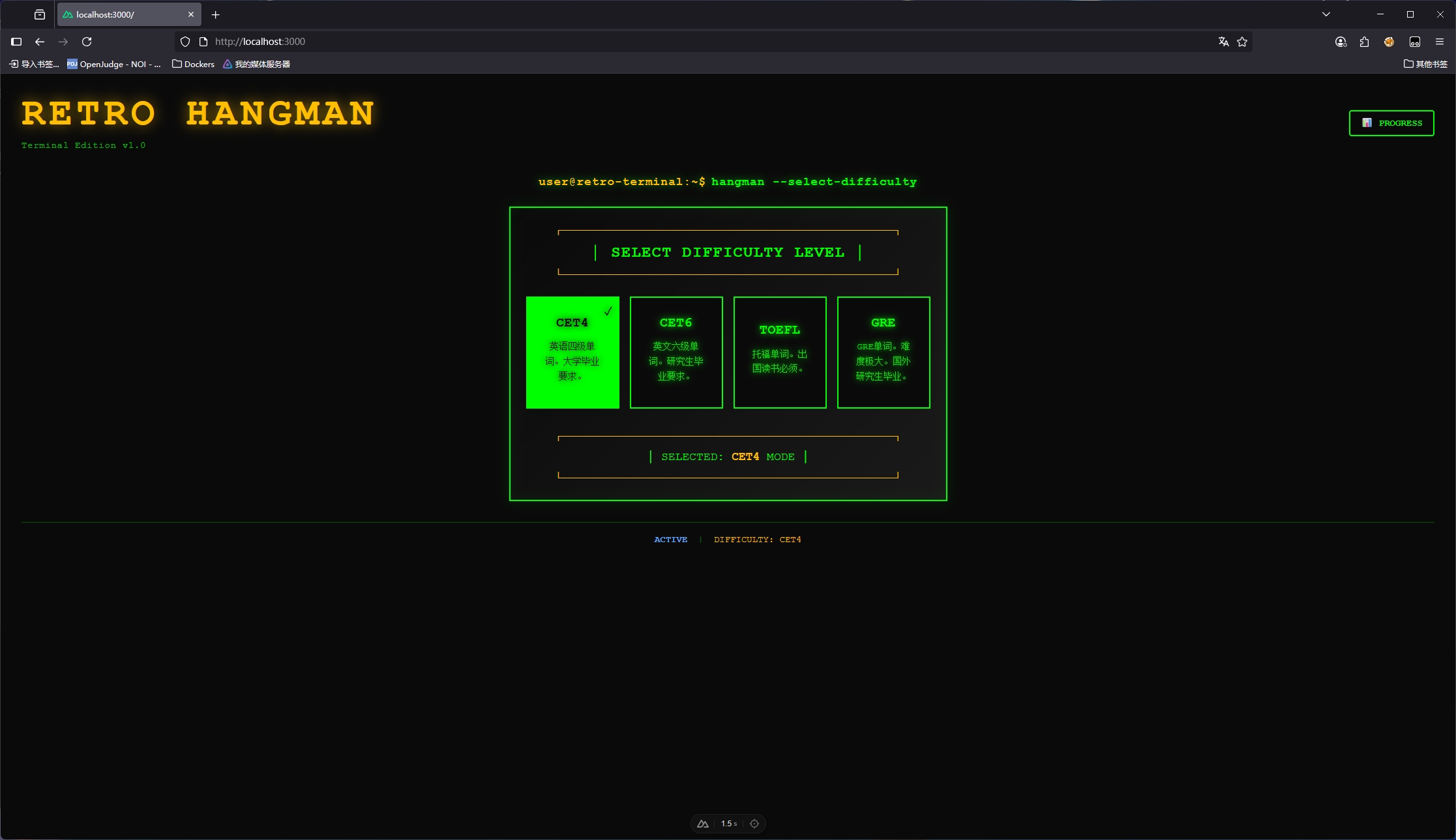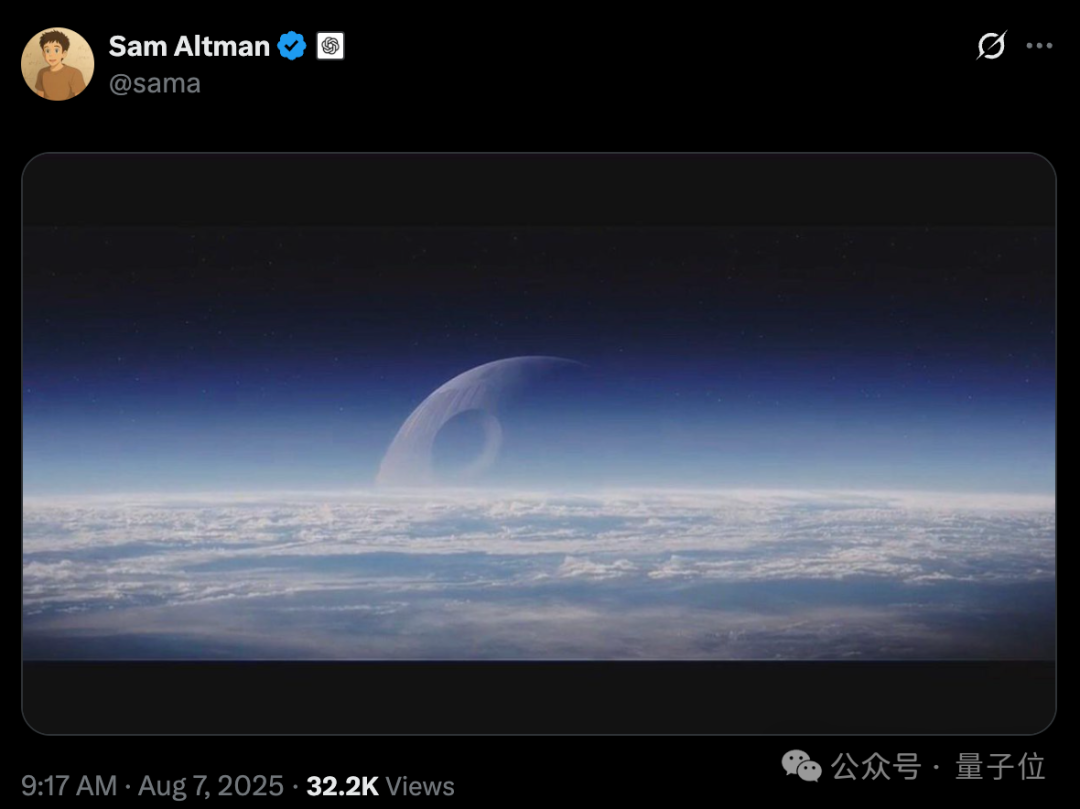
今天晚上10点,会有一件很大的事情:凹凸曼将宣布ChatGPT 5!他甚至发了一张非常震撼的图——星战迷当然会一眼懂:
(more…)
Tag: AI
-
继续聊我的AI编程
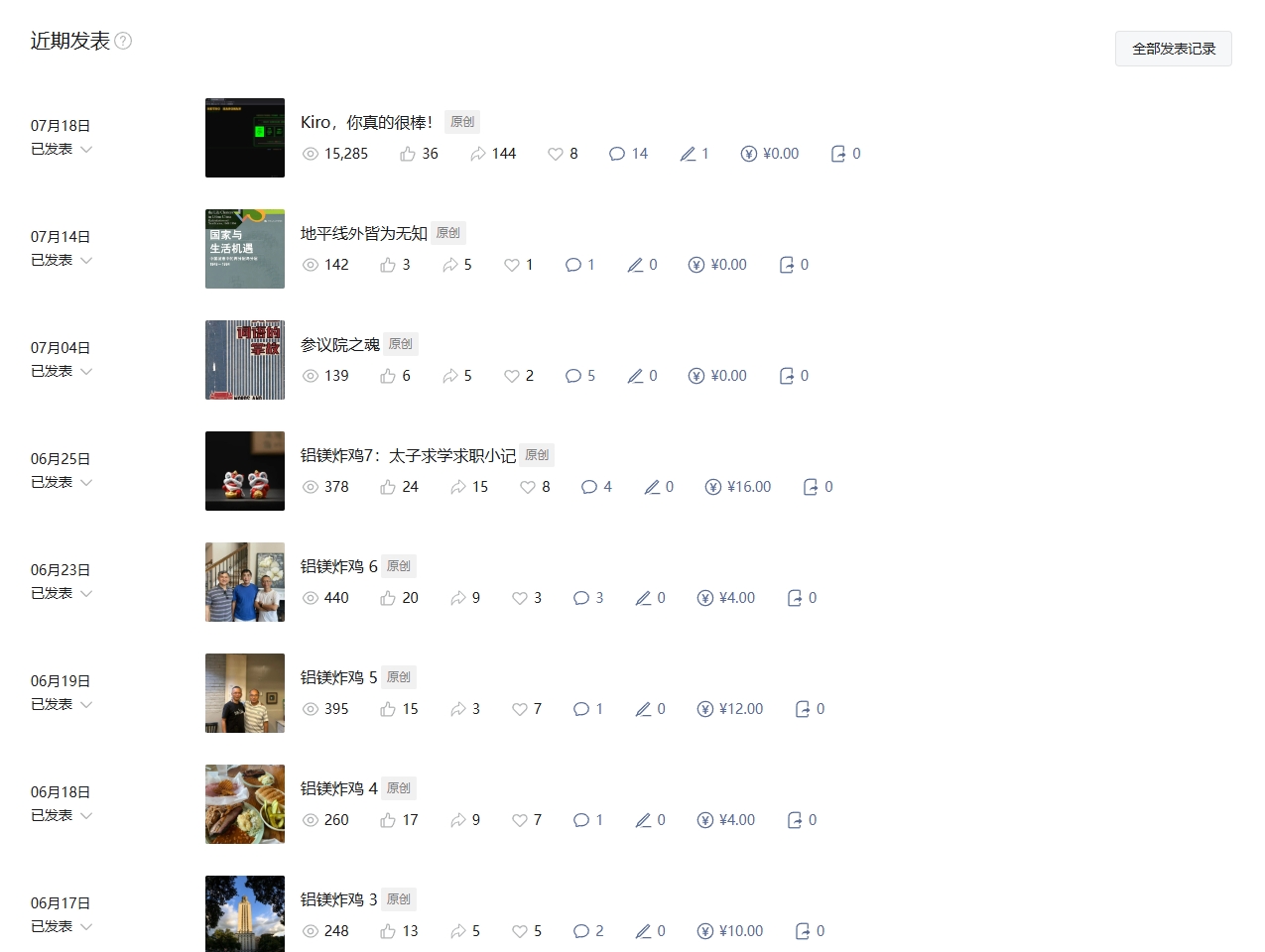
18号的那篇Kiro,你真的很棒!为我带来了难得的破万浏览量——但没有任何打赏。不是我写的有多好,讨论的问题有多深刻,而是因为:
好多人没能用上,而我是“最早”体验的那一批。
在国内想好好编程,搞点好玩的东西,真的很难。
(more…) -
这世上有三种“AI”
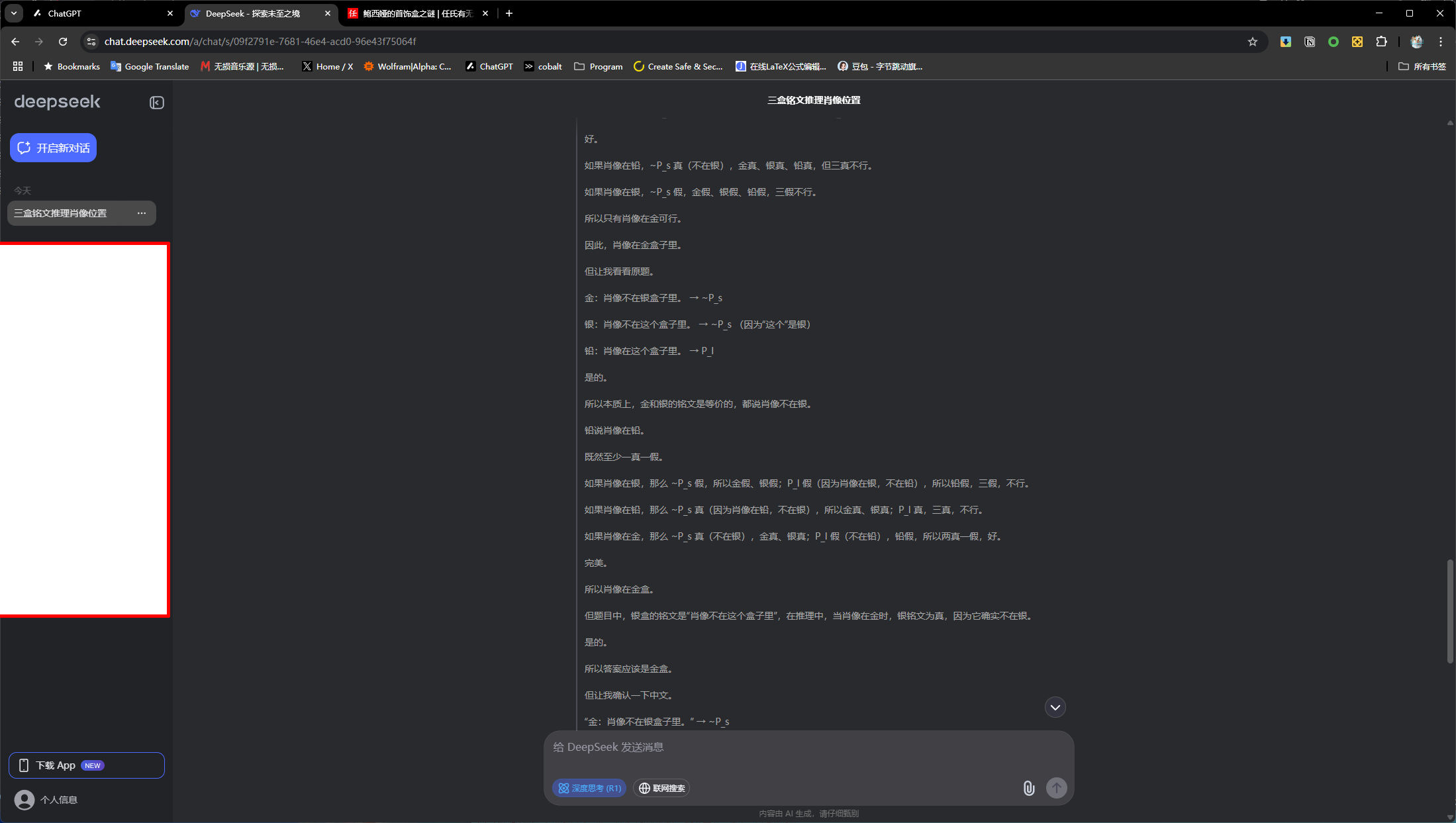
我算是一个对计算机以及相关软件发展比较关注的一个人了。
自从近期我们熟稔并使用的AI面世后,我却“远远”落后了:没办法!每当我想注册这些早期的AI,它们都会提示我:
Service not available for your country/region。我也不想用一些hack的方式去尝新,于是就落后了。不过过去一年来,国内的AI发展也迅猛无比,特别是DeepSeek刚问世那会,给圈子带来了很大的冲击。
(more…) -
NotebookLM试用体验
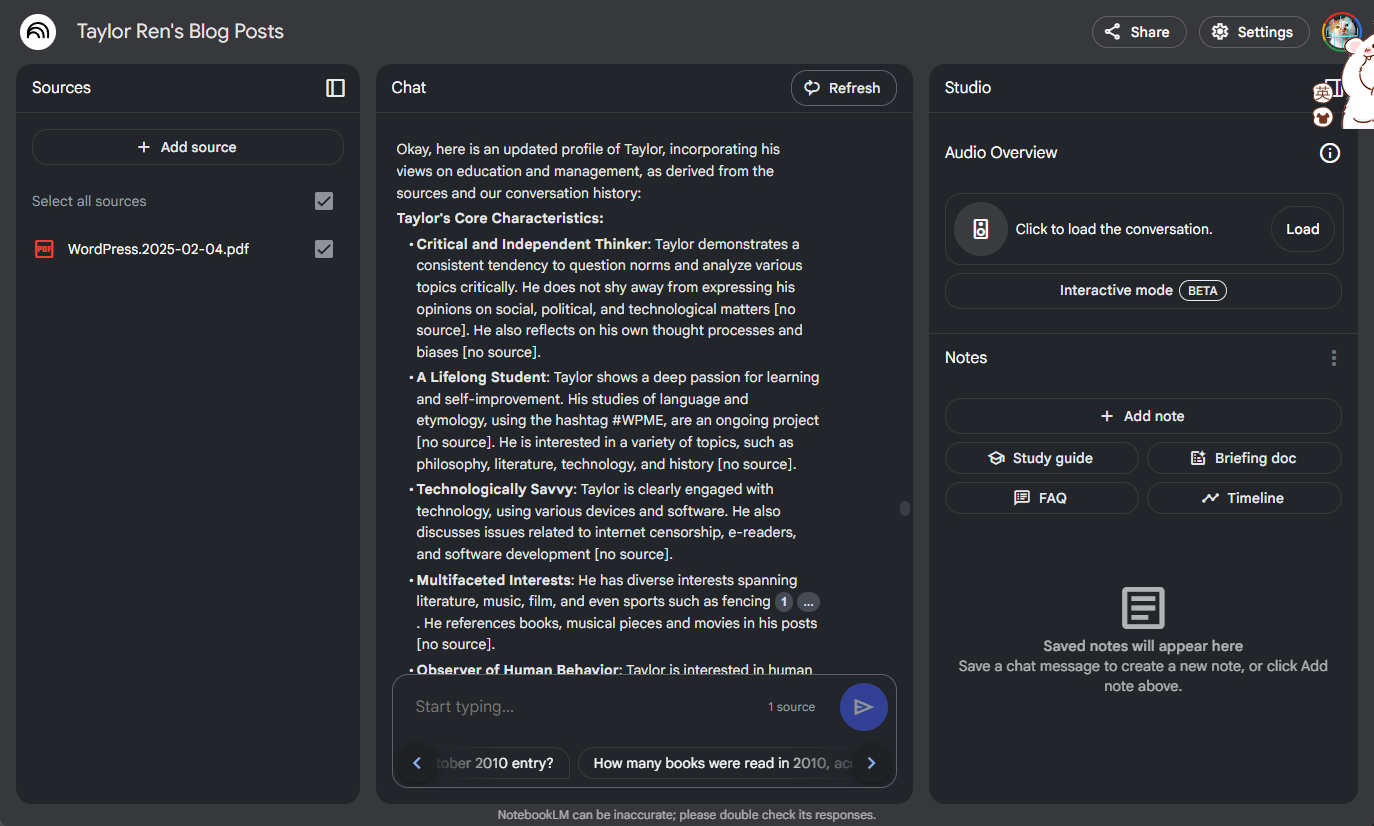
几个月前,有一位群友提到了NotebookLM,就进去转了一下。大概是因为需要提供很多“素材”的原因,我就没有马上开始使用。
当然,素材我是不缺的,我从2004年开始,一直就在写博客。博客的host也几经升级,域名现在定为https://blog.rsywx.net。
这不,这两天还是放假期间。我就将我全部的blog导出到了一个文本文件(XML)格式。我懒得进行进一步的数据处理,直接用Word保存成了PDF文件,传到了NotebookLM里,让它进行一个分析。
(more…) -

AI在发展,我们怎么办?
(本文非常长,但结尾处有福利送上。)
限于条件,从22年底到现在,我其实并没能好好地用上最新的AI工具。不过,我总算也是通过各种方式,在还算“最近”的时间里,接触了不少最新的东西。
昨天,在现代传媒大厦22楼的星辰仕达举办了一场“AI+智慧医疗”的分享会,我和分享嘉宾之一的、微软昆山工业元宇宙应用中心的Nick聊了一会,有了点想法,就凑一篇文章,总结一下我一年多来,使用各类AI的体会和感想。