AI时代,上网的两个重要动作:搜索和浏览被重新定义了。
而且我还注意到,还有一个新的动作需要被加入。我还没想好这个动作应该怎么命名,暂且先用“整理”名之。
(more…)

18号的那篇Kiro,你真的很棒!为我带来了难得的破万浏览量——但没有任何打赏。不是我写的有多好,讨论的问题有多深刻,而是因为:
好多人没能用上,而我是“最早”体验的那一批。
在国内想好好编程,搞点好玩的东西,真的很难。
(more…)
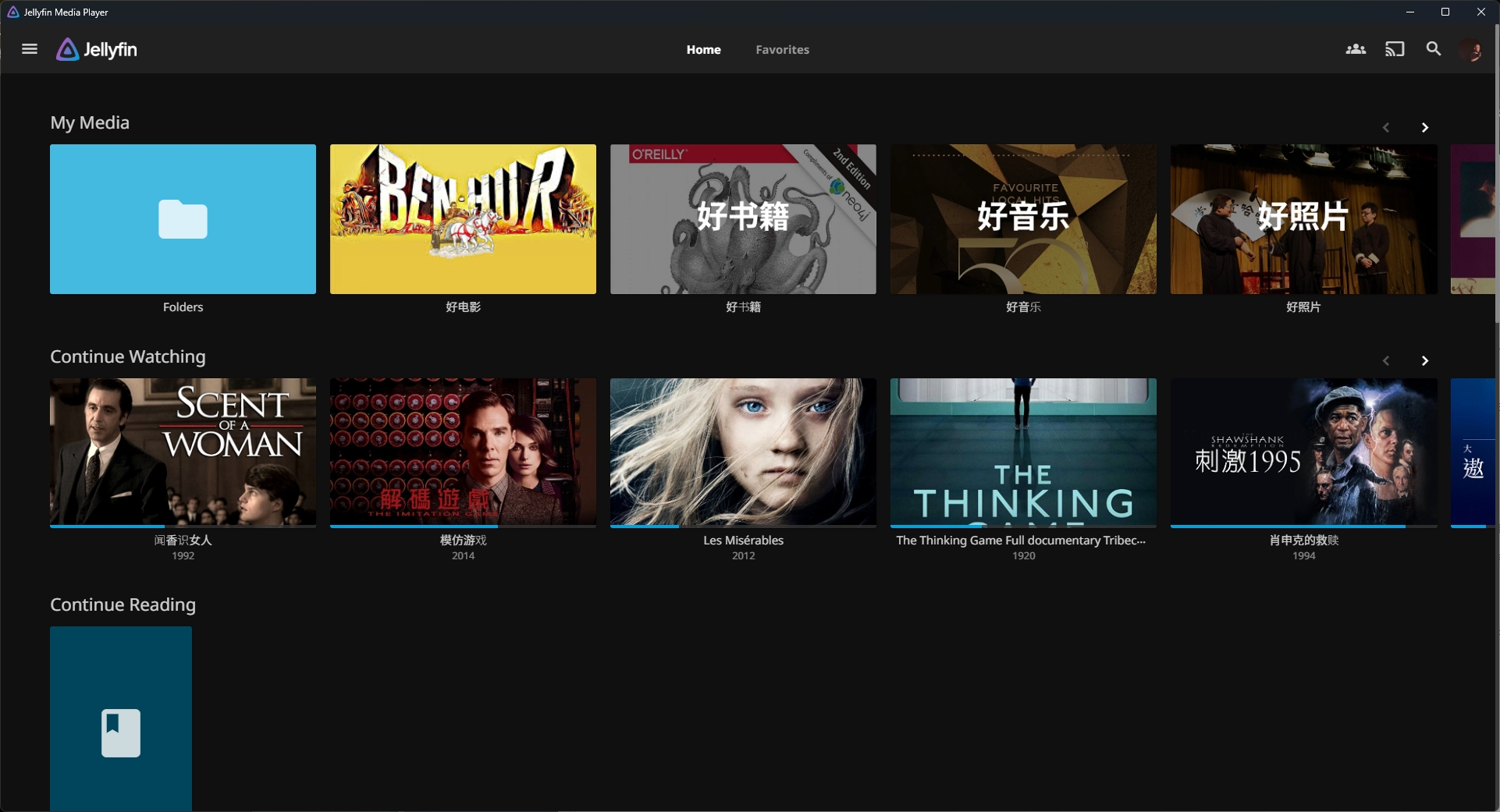
23年底的时候,我写过一篇“一个家里可能用得到的软件”,收获了不少阅读量。一年多过去了,我还在不断地尝试着完善我的个人(包括家庭)影音体验。
本篇文字算是上一篇的后续,聊聊我这一年多来又搞了些什么花样。
(more…)
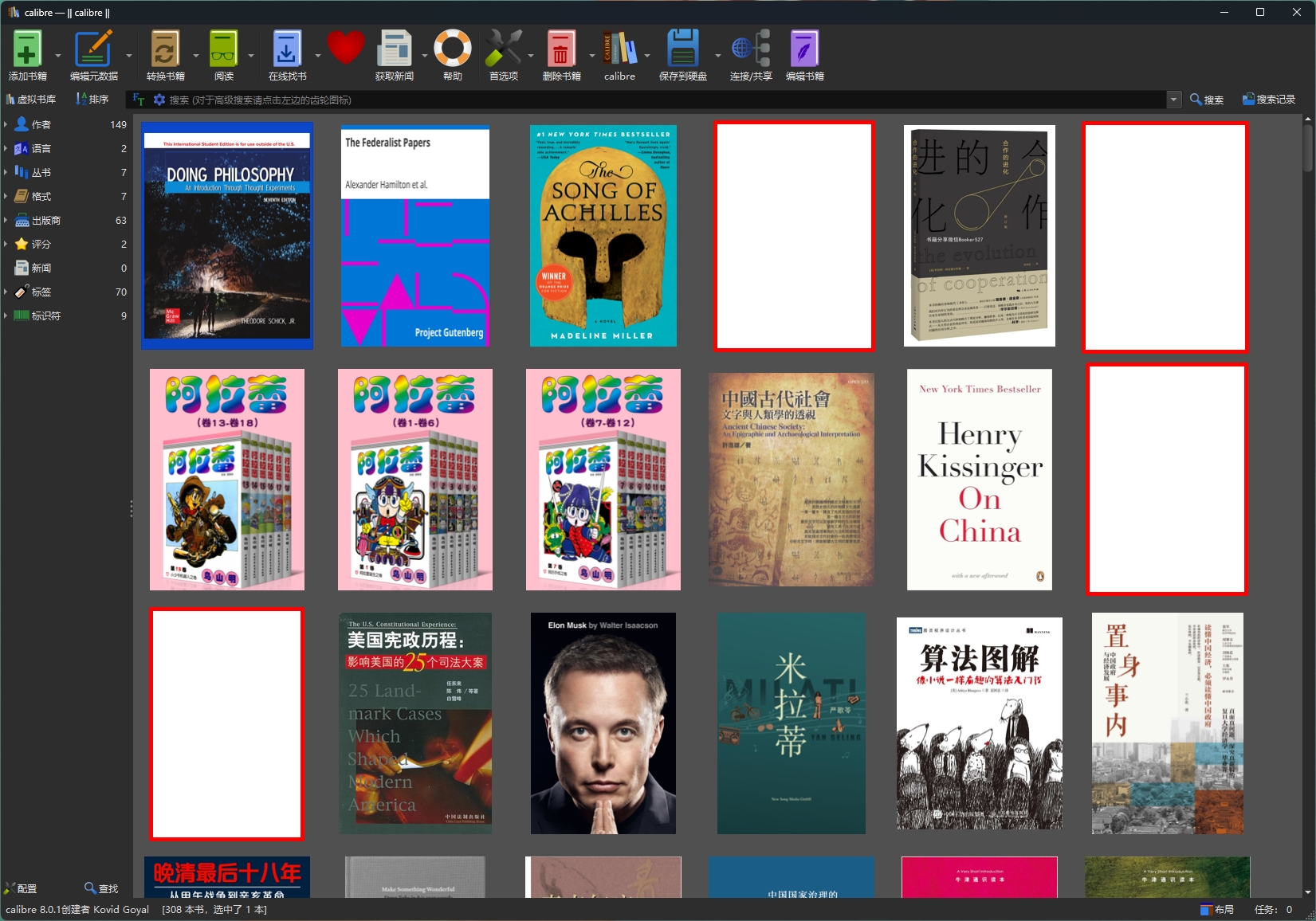
在我的台式机上,我一直用免费的Calibre来管理我的电子书收藏。现在的人们已经太习惯于在手机上进行所有的操作了——包括读书,所以这样的一个小众软件能保持这么多年的持续更新,确实很不容易。
今天因为要导入一本我刚找到的书,检查了一下Calibre的更新,发现它悄悄地进行了版本大升级,从原来的7.X一下子跳到了8.0。